In Softwareprojekten hat man schnell ein umfangreiches Wissen aufgebaut. Dieses wichtige Wissen, wie technische Entscheidungen, Funktionshistorie, Konfigurationsdetails usw., verteilt sich häufig über Tickets, Wikis, Chat-Threads und Dokumente.
Die Suche nach einer bestimmten Antwort kann Minuten oder Stunden dauern. Diese „Wissenssuche” kann nicht ganz unerhebliche versteckte Kosten verursachen, die die Entwicklung verlangsamen und die Projektteilnehmer frustrieren.
Die Wissenssuche ist die Zeit, die Teams mit der Suche nach Informationen verbringen, anstatt etwas aufzubauen. Diese Suche hat einen direkten Einfluss auf die Geschwindigkeit, mit der im Projekt gearbeitet wird und ist quasi eine unsichtbare Produktivitätsbremse.
Unserem Team ist aufgefallen, dass Routinefragen zu Verzögerungen von 30 bis 120 Minuten führten, während ein Entwickler Dokumentationen, Tickets oder Nachrichten durchforstete. Die Einarbeitung eines neuen Entwicklers oder Produktverantwortlichen dauerte oft ein bis zwei Wochen, während er versuchte, sich in die jahrelange Projekthistorie einzuarbeiten.
Um dieses Problem zu lösen, haben wir den AI Project Assistant entwickelt. Er fungiert als intelligente Wissenszentrale für jedes Kundenprojekt und macht aus dem verteilten Wissen einen aktiven Gesprächspartner.
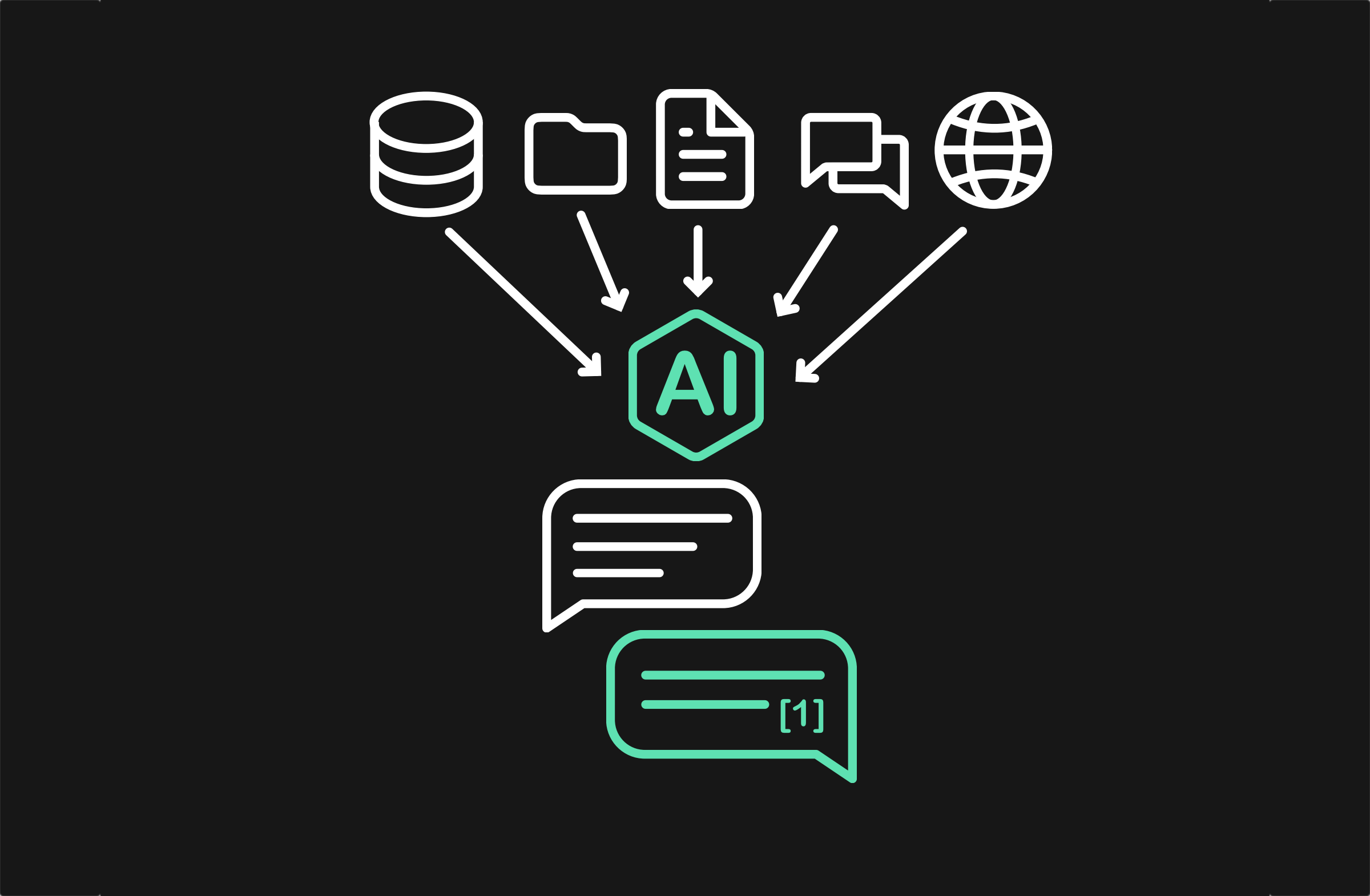
Der Assistant ist mehr als eine reine Suchfunktion. Er nutzt ein Large Language Model (LLM), um auf die gesamte Projekthistorie zuzugreifen, Fragen in natürlicher Sprache zu verstehen und innerhalb von Sekunden klare, zitierte Antworten zu liefern.
Der Assistent verbindet sich mit allen primären Datenquellen, um ein vollständiges Abbild zu erstellen. Er indexiert Projektmanagement-Tickets (Beschreibungen, Kommentare, Status), Wiki-Seiten, technische Dokumente, PDF-Uploads und relevante Chat-Nachrichten.
Die Teams greifen direkt über die Plattformen darauf zu, die sie bereits täglich nutzen, beispielsweise Slack. Sie können Fragen in einem privaten 1:1-Chat stellen oder den Bot in einem gemeinsamen Kanal markieren, um die Antworten für alle sichtbar zu erhalten.
Erfahren Sie mehr über die Architektur, die wichtigsten Kennzahlen und Anwendungsfälle in unserer Case-Study.
Los geht's!Unser Team merkt die Auswirkungen bereits zum Beispiel bei der Einarbeitung: Neue Teammitglieder sind in weniger als einem Tag einsatzbereit, statt wie bisher in ein bis zwei Wochen.
Diese Veränderung bedeutet, dass unsere Teams und Kunden schneller vorankommen. So können sich alle darauf konzentrieren, neue Funktionen zu entwickeln, anstatt nach vorhandenen Informationen zu suchen.
Der Umgang mit Kundendaten erfordert ein hohes Maß an Vertrauen. Wir haben den Assistenten von Grund auf mit einem strengen Opt-in-Zugriffsmodell entwickelt — klassisches Privacy by Design.
Kundendaten werden in vollständig getrennten, isolierten Sammlungen gespeichert. Der Zugriff ist granular, d.h. Benutzer werden nur den spezifischen Projekten zugeordnet, für die sie eine Berechtigung haben.
Wir entwickeln den Assistenten auf Basis der Rückmeldungen des Teams und unserer Kunden weiter. Unsere Roadmap konzentriert sich auf tiefere Integrationen und einen breiteren Zugriff.
Dazu gehören neue Zugangskanäle wie eine webbasierte Chat-Schnittstelle und eine direkte IDE-Integration für Entwickler. Außerdem erweitern wir die Datenintegration um Jira, Confluence und Quellcode-Repositorys. Das Ziel ist es, eine vollständige, abfragbare Historie jedes Projekts zu erstellen.
Durch die Bereitstellung eines zentralen Zugriffs auf Projektwissen in natürlicher Sprache entlasten wir unsere Teams und Kunden. Der Fokus verlagert sich von der Suche nach bestehenden Entscheidungen hin zu neuen, fundierten Entscheidungen.
Eine detaillierte Aufschlüsselung des Projekts, einschließlich der vollständigen Liste der wichtigsten Ergebnisse, der technischen Architektur und spezifischer Anwendungsfälle für Kunden/Entwickler, finden Sie unter:
Erfahren Sie, wie ein KI-Projektassistent Wissen aus verschiedenen Quellen zentralisiert und Fragen mit Quellenangaben beantworten kann.



17.07.26